PyTorch Custom Datasets
In the last session, 04 PyTorch Computer Vision, we looked at how to build computer vision models on an in-built dataset in Pytorch (FashionMNIST).
The steps we took are similar across many different problems in machine learning. Find a dataset, turn the dataset into numbers, build a model (or find an existing model) to find patterns in those numbers that can be used for prediction. PyTorch has many built-in datasets used for a wide number of machine learning benchmarks, however, you’ll often want to use your own
What is a custom dataset?
A custom dataset is a tailored collection of data specific to the problem you’re solving.
It can include almost anything, such as:
- Food images for a classification app like Nutrify.
- Customer reviews with ratings for sentiment analysis.
- Sound samples with labels for a sound classification app.
- Purchase histories for building a recommendation system.
PyTorch has many built-in datasets used for a wide number of machine learning benchmarks, however, you’ll often want to use your own custom dataset.

While PyTorch provides a variety of built-in functions for loading datasets through libraries like TorchVision, TorchText, and TorchAudio, these predefined tools may not always meet the specific needs of your project.
In such cases, you can create a custom solution by subclassing torch.utils.data.Dataset. This approach allows you to define a dataset tailored to your unique requirements. By implementing the __init__, __len__, and __getitem__ methods, you can handle specific data formats, apply custom preprocessing, and control how data samples are accessed and utilized during training.
Customizing a dataset gives you the flexibility to work with non-standard data types, formats, or use cases that aren’t supported by default PyTorch utilities. This ensures your model has access to the data it needs in exactly the way you intend.
What We’re Going to Cover
In this section, we’ll apply the PyTorch Workflow introduced in pytorch workflow and pytorch classification to solve a computer vision problem.
Unlike previous examples where we used pre-built datasets from PyTorch libraries, we’ll work with a custom dataset containing images of pizza, steak, and sushi. This provides an opportunity to explore how to handle unique datasets that aren’t available out-of-the-box.
Our objective is to load these custom images, preprocess them appropriately, and then build a model capable of learning from this data. By the end, our model will be able to make predictions on unseen images, demonstrating its ability to classify different types of food accurately.
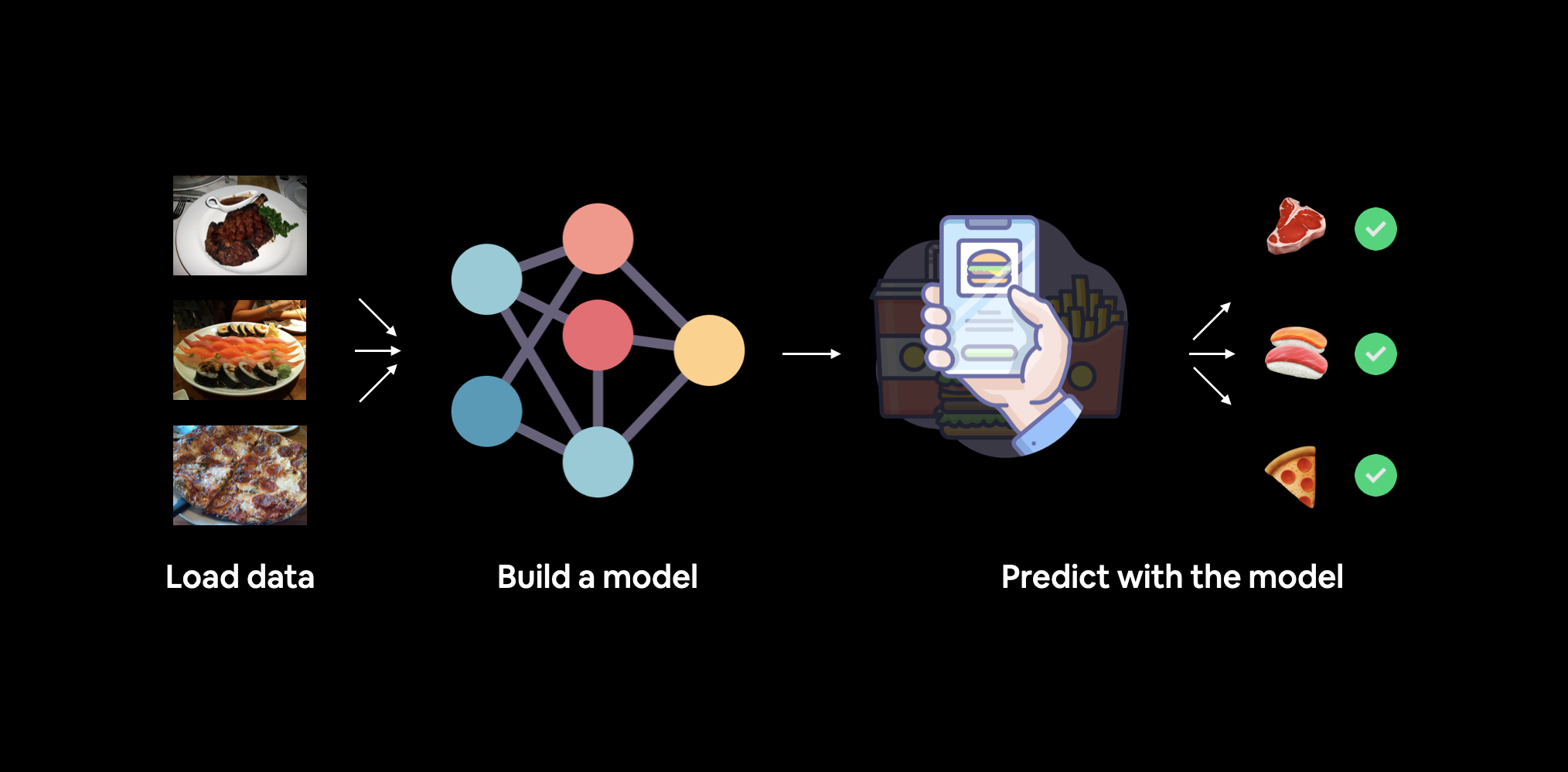
torchvision.datasets as well as our own custom Dataset class to load in images of food and then we'll build a PyTorch computer vision model to hopefully be able to classify them. Specifically, we’re going to cover:
| Topic | Contents |
|---|---|
| 0. Importing PyTorch and setting up device-agnostic code | Let's get PyTorch loaded and then follow best practice to setup our code to be device-agnostic. |
| 1. Get data | We're going to be using our own custom dataset of pizza, steak and sushi images. |
| 2. Become one with the data (data preparation) | At the beginning of any new machine learning problem, it's paramount to understand the data you're working with. Here we'll take some steps to figure out what data we have. |
| 3. Transforming data | Often, the data you get won't be 100% ready to use with a machine learning model, here we'll look at some steps we can take to transform our images so they're ready to be used with a model. |
4. Loading data with ImageFolder (option 1) | PyTorch has many in-built data loading functions for common types of data. ImageFolder is helpful if our images are in standard image classification format. |
5. Loading image data with a custom Dataset | What if PyTorch didn't have an in-built function to load data with? This is where we can build our own custom subclass of torch.utils.data.Dataset. |
| 6. Other forms of transforms (data augmentation) | Data augmentation is a common technique for expanding the diversity of your training data. Here we'll explore some of torchvision's in-built data augmentation functions. |
| 7. Model 0: TinyVGG without data augmentation | By this stage, we'll have our data ready, let's build a model capable of fitting it. We'll also create some training and testing functions for training and evaluating our model. |
| 8. Exploring loss curves | Loss curves are a great way to see how your model is training/improving over time. They're also a good way to see if your model is underfitting or overfitting. |
| 9. Model 1: TinyVGG with data augmentation | By now, we've tried a model without, how about we try one with data augmentation? |
| 10. Compare model results | Let's compare our different models' loss curves and see which performed better and discuss some options for improving performance. |
| 11. Making a prediction on a custom image | Our model is trained on a dataset of pizza, steak and sushi images. In this section we'll cover how to use our trained model to predict on an image outside of our existing dataset. |
Importing PyTorch and setting up device-agnostic code
1
2
3
4
5
import torch
from torch import nn
# Note: this notebook requires torch >= 1.10.0
torch.__version__